So you want to scrape lots of data from the internet using Node Crawler? No problem. You’ll need to know JavaScript, jQuery, and a bit of Node.
First things first:
1) goto Terminal and create a new javascript folder called node crawler and save a file called “craigslist.js”
2) in your folder, run npm install crawler
3) Make sure you know how to select elements from the DOM using jQuery
4) Pick a site you want to scrape from. In our example, I’m using craigslist.
Lets jump into it and I’ll show you the code in full and then break it down piece by piece:
var Crawler = require("crawler");
var url = require('url');
var fs = require('fs');
var jsonArray = [];
var craigslist = new Crawler({
maxConnections : 10,
callback : function (error, result, $) {
$('.row').each(function(index, a) {
var jsonOutput = {};
var dataSplit = $(a).text().split(' ');
jsonOutput.price = dataSplit[1];
jsonOutput.date = dataSplit[5] + dataSplit[6];
jsonOutput.siteLink = "http://sfbay.craigslist.org" + $(a).children().attr('href');
console.log("price:" + jsonOutput.price + " date:" + jsonOutput.date
+ " date:" + jsonOutput.siteLink)
jsonArray.push(jsonOutput)
});
var rangeNumber = $($('.range')[0]).text().split(' ')[2]
console.log("We are on item range: " + rangeNumber)
var toQueueUrl = 'http://sfbay.craigslist.org/search/bia?s=' + rangeNumber
if (parseInt(rangeNumber) < 1000) {
craigslist.queue(toQueueUrl);
} else {
fs.appendFile('craigsListData.txt', JSON.stringify(jsonArray), function (err) {
if (err) throw err;
console.log('The "data to append" was appended to file!');
});
}
}
});
craigslist.queue('http://sfbay.craigslist.org/search/bia')
when you run node craigslist.js This will give you a result such as this:
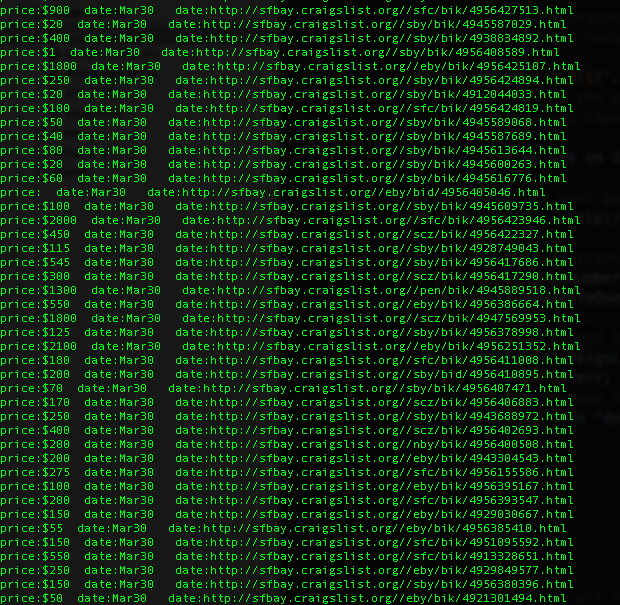
Awesome, lets break down how it works:
Lines 1 -3: All of our require statements. Only module you need to require is crawler.
var Crawler = require("crawler");
var url = require('url');
var fs = require('fs');
Lines 7-9: instantiate a new Crawler and pass in standard options. on line 9, create your callback function.
var craigslist = new Crawler({
maxConnections : 10,
callback : function (error, result, $) {
line 11: This will loop over every instance of .row class on the page. As you can see, the row class contains all the pertinent info we need.
$('.row').each(function(index, a) {
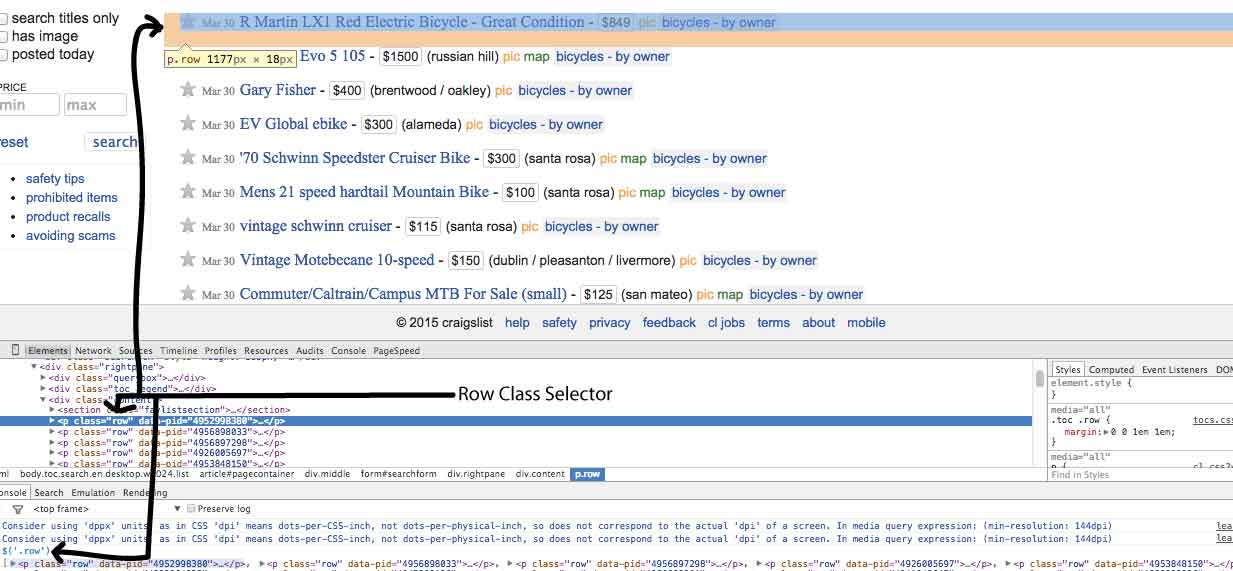
lines 14-18: using jQuery, select data you want to save and put that data into the json object we've created
var dataSplit = $(a).text().split(' ');
jsonOutput.price = dataSplit[1];
jsonOutput.date = dataSplit[5] + dataSplit[6];
jsonOutput.siteLink = "http://sfbay.craigslist.org" + $(a).children().attr('href')
We want to append that data to the JSON array, and when all is complete -- we want to find the next page.
Go recursion go!
Line 26: Here we look at the an item on the on the HTML document that we can pass into our crawler and find the the next page. Thankfully, craigslist gives us a range element that we can pass into the URL to find the next 100 elements. We extract that of course.
var rangeNumber = $($('.range')[0]).text().split(' ')[2]
Line 30: Create a 'link' to pass into the crawler based on the range we just scraped
var toQueueUrl = 'http://sfbay.craigslist.org/search/bia?s=' + rangeNumber
Lines 32-38: We want our base case -- which is "If the range is less than 1000, run the next link into our crawler. Otherwise, save all the data to our system."
if (parseInt(rangeNumber) < 1000) {
craigslist.queue(toQueueUrl);
} else {
fs.appendFile('craigsListData.txt', JSON.stringify(jsonArray), function (err) {
if (err) throw err;
console.log('The "data to append" was appended to file!');
});
Line 43: Start the recursion and pass in the first page
craigslist.queue('http://sfbay.craigslist.org/search/bia')