Posts by Admin
What happens when your app hits the frontpage of reddit
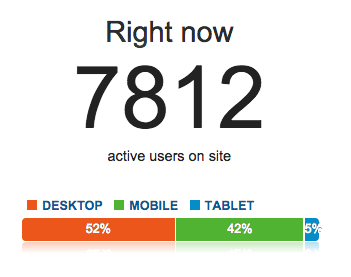
What happens when your app hits the frontpage of reddit
October 31, 2015
Creating a recursive web scraper with Node Crawler

Creating a recursive web scraper with Node Crawler
March 30, 2015



